The Data Browser has a new look!
Updating the Data Browser
Representing more than 11,000 patients, each analyzed across multiple molecular dimensions, The Cancer Genome Atlas (TCGA) represents an incredibly rich data resource. However, navigating this landscape to find exactly the data that is most interesting can be challenging – particularly when information is spread across multiple sources. To address this difficulty, we applied semantic web technologies to build a rich knowledge base containing more than 140 clinical, biospecimen and analytical properties that can be used to describe cancer genomics data, like TCGA.
This knowledge base can be queried programmatically using the query language SPARQL or via a simplified API. Additionally, in order to make building complex queries accessible to a wide audience, we developed a visual query engine termed the Data Browser. The Data Browser aims to make it easy for researchers to quickly search across more than 100 different properties to find exactly the data that they are interested in. Since the early access release of the CGC in November 2015, we’ve been collecting feedback, performing usability labs and evaluating the different ways that researchers use the Data Browser to quickly find the data they are most interested in.
A few common themes emerged from this analysis:
- Researchers liked that the data browser allowed them to build rich queries that would be difficult or impossible to create using alternative approaches, but sometimes this took longer than expected and complex queries could be difficult to interpret.
- Researchers liked the ability to ‘count’ the number of entities matching a query, but didn’t like having to refresh each count one-by-one when the query changed.
- Researchers liked the ability to use branch points to find data matching multiple criteria, but the tabular representation of this data wasn’t always intuitive.
Today, we’re excited to announce a complete redesign of the data browser visual interface. The primary goal of the redesign was to make it faster and easier for you to find TCGA data that is most interesting for you. And, once you’ve found this data, you can analyze and learn from it straight away using either pre-built workflows or your custom tools.
We hope you’ll take the new data browser for a spin! When you do, you can expect the following improvements:
Properties are now more logically linked to their corresponding entity
This makes building and understanding queries faster and more intuitive. For example, compare the same query in the old data browser (left) with the redesigned version (right).
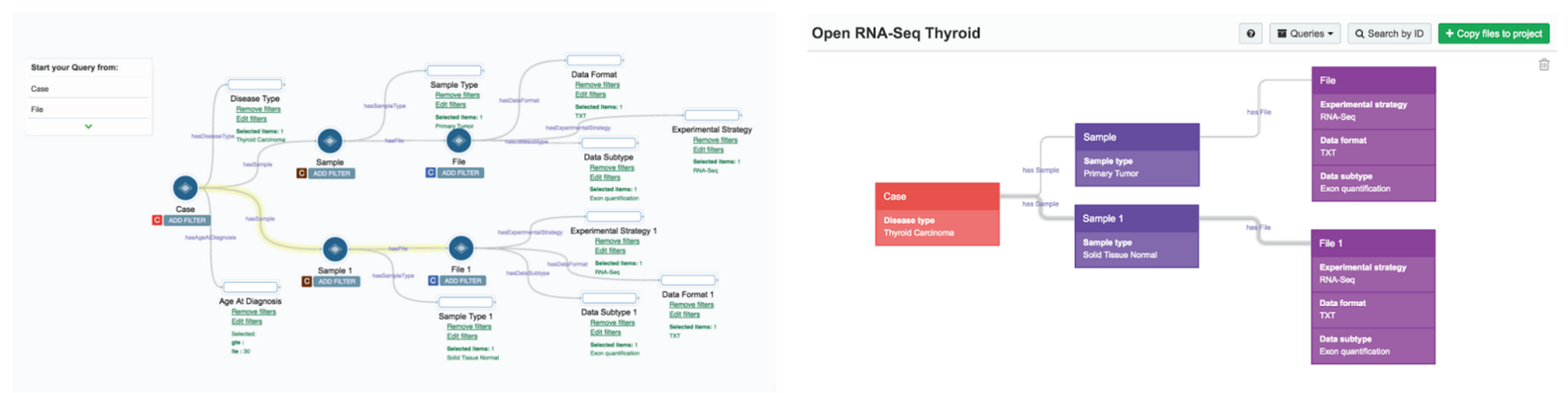
The results table is more intuitive and interactive
The ability to create queries with branches (as shown above), while powerful, can make representing the results in a tabular fashion challenging. The redesigned table allows you to select each entity and inspect its entity ID as well as any selected property values through the graph. When you modify a query, the counts tabs for each entity become greyed out, to indicate that the total numbers for the entities satisfying the query can be updated. Selecting a single entity tab will recount the matching entities; or you can chose to recount all entities in a single click.

In addition to these updates, we’ve made improvements throughout the Data Browser interface to make it easier, faster and more enjoyable to use. We are grateful to the researchers who provided feedback on the first iterations of the interface and look forward to continuing to improve the CGC to help you learn from large datasets like The Cancer Genome Atlas.
We hope you’ll enjoy using the new Data Browser – as you do please don’t hesitate to contact us using the forum or email at cgc@sbgenomics.com with any questions or feedback.