Data democratization advances oncology research
Next week Seven Bridges will be at the Molecular Medicine Tri-Conference in San Francisco, California. Gaurav Kaushik, one of our Scientific Program Managers, will be sharing our work on the Cancer Genomics Cloud (CGC) as part of the conference’s informatics track.

Launched publicly in 2016, the Seven Bridges CGC is an NCI Cancer Genomics Cloud Pilot. It enables widespread access to The Cancer Genome Atlas (TCGA), a public collection of omics data from over 11,000 patients and 33 types of cancer. In his talk, Gaurav will discuss how the CGC democratizes data and advances oncology research.
A research paradigm that requires data democratization
The field of genomics has a long history of making data openly available to the research community. From the beginning, the Human Genome Project established the precedent that all human sequencing data should be made available online.
Specifically in oncology research, sharing genomic and other sequencing data is necessary. Cancer drivers, or genetic alterations that lead to disease, follow a long-tail distribution where few are highly prevalent in the patient population and most are rare. As a result, identifying a mutation that occurs in 2% or more of patients with cancer requires the analysis of 100,000 tumor samples. Democratizing data allows researchers to share and combine enough data to enable driver discovery.
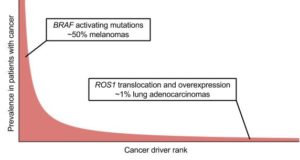
The long-tail distribution of cancer driver prevalence. Few drivers are highly prevalent, while most drivers are rare.
In addition to serving as the basis for driver discovery, democratizing cancer data advances research across the board. When data are widely available, more researchers can bring their diverse expertise to the field, discuss and validate each other’s work, and collaborate across institutional lines. Removing logistical barriers to data availability enables faster, more effective research.
Democratized data = accessible + usable
The democratization of cancer data involves two important factors, making the data accessible and usable.
Accessible data
Before the CGC, access to the petabytes of TCGA data was limited to institutions with the time and storage resources to download them. Now that TCGA data are stored centrally on the CGC, all researchers can log in for immediate access, regardless of their country or institution. There are currently over 1,000 CGC users from over 150 institutions across over 30 countries. Researchers are spread out among different sectors, including academia, government, and industry. Notably, only 21% of users are from top 50 NIH-funded institutions.
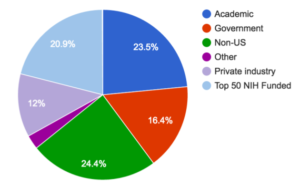
Distribution of CGC users among different types of institutions. Image by Gaurav Kaushik.
Usable data
Not only do cancer data need to be widely accessible, they also need to be usable by all researchers. Data are not democratized unless all researchers can readily understand and use them. To this end, the CGC includes a metadata framework that labels and organizes data files according to a standardized scheme. Researchers can use a visual tool to interactively browse and select files of interest, according to properties such as cancer type, radiation therapy, and data format. Once data have been selected, researchers can analyze them on the CGC using preloaded or their own bioinformatics software.
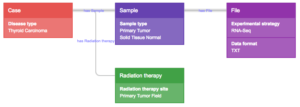
Screenshot of the CGC Data Browser tool. Users can interactively select data of interest, for example RNA-Seq count files for thyroid tumor and normal tissue samples from patients who received local radiation therapy.
Meet us at TRI-CON
In addition to Gaurav’s presentation, we will be demoing the CGC and the Seven Bridges Platform at our booth in the exhibit hall.
